Efficient Integration of multi-channel Information for DNN-based Speech Separation using Attention Mechanism and Transfer Learning
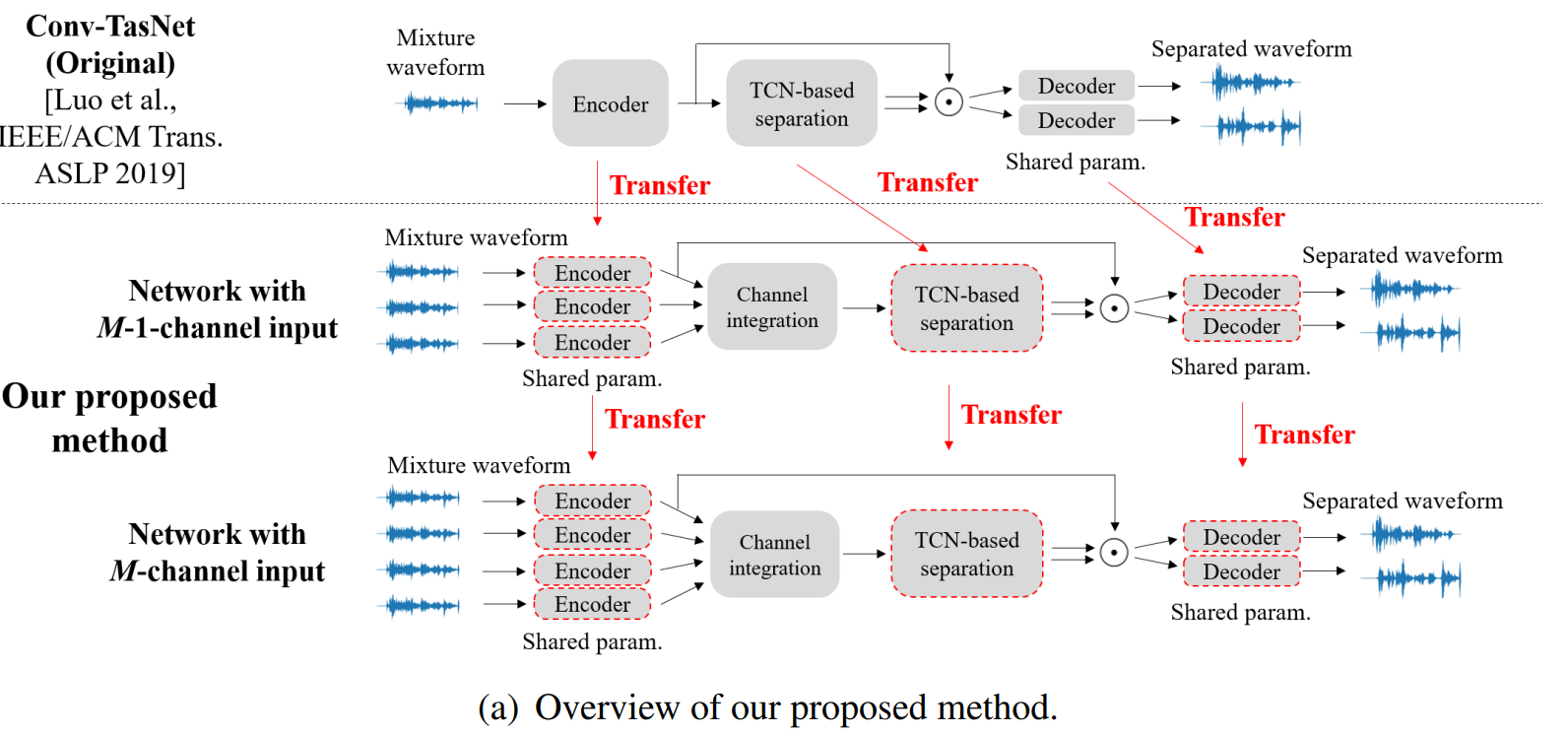
Although deep-learning-based methods have significantly improved the performance of speech separation over the past few years, efficient integration of multi-channel signals still remains an open question. The main problem is that the performance tends to degrade when the angle difference between speakers is small. In addition, the computational complexity of several existing algorithms scales with the number of input channels. We propose an attention-based architecture to adaptively process signals with any angle difference. Its computational complexity hardly increases even when the number of input channels increases. Moreover, we propose a transfer learning framework that converts a network that works on singlechannel input to one that works on multi-channel input. This framework helps our proposed architecture obtain better attention weights and contributes to improving the separation performance. Experiments showed that our proposed method achieved the state-of-the-art performance while remaining computationally efficient. Paper/ Under Review at ICASSP 2021
Oluwafemi Azeez
Research Engineer (Team Lead)
My research interests include Reinforcement learning and computer vision.